Die Chancen von KI
Verantwortungsvolle KI im Recruiting bietet eine echte Chance, Diskriminierung systematisch zu reduzieren. Sämtliche Diskriminierungsmuster, die sich in einer KI manifestieren, stammen ja aus historischen Diskriminierungen durch menschliche Entscheidungen. Indem wir diese Biases in KI identifizieren und entfernen, kann KI dabei helfen, das reale Ausmaß an Diskriminierung gegenüber dem Status-Quo drastisch zu reduzieren. Wir möchten durch klare ethische Leitlinien und aktiver Forschung dazu beitragen, dass Kandidat:innen dank KI tatsächlich nach individuellen Fähigkeiten und Eignung ausgewählt werden – und nicht nach Stereotypen auf Basis von Geschlecht, Herkunft, Alter oder anderen personenbezogenen Merkmalen.Mit KI lassen sich Diskriminierung und Grundrechtsverletzungen im Vergleich zu menschlichen Entscheidungsprozessen systematisch reduzieren! Wir verstehen uns als Vorreiter in der Entwicklung dazu geeigneter KI.
- Grundrechte in Bezug auf die Verwendung von Daten für das KI-Training
- Grundrechte bei der Anwendung von KI im Allgmeinen
- Grundrecht der Diskriminierungsfreiheit im Speziellen
100% human-in-the-loop
Unabhängig von allen Anstrengungen zur Weiterentwicklung und Innovation im Bereich verantwortungsvoller KI führen wir bis auf Weiteres eine 100%-Qualitätsprüfung der KI-Ergebnisse durch hochqualifizierte Mitarbeiter:innen durch. Insbesondere die KI-generierten Shortlists werden von hochqualifizierten Mitarbeiter:innen mit mehrjähriger Berufserfahrung im Active Sourcing kontrolliert, bevor sie für die Ansprache von Kandidat:innen verwendet werden. Im Zuge der menschlichen Aufsicht gewinnen wir strukturierte und repräsentative Qualitätsdaten, die wir in den Entwicklungsprozess zurückfließen lassen.Gestaltung der Datensätze
Ein unverzichtbarer Ansatzpunkt zur Vermeidung von Bias in KI-Systemen ist die Gestaltung und Überwachung der Trainingsdaten. Diesbezüglich ergreifen wir die folgenden Maßnahmen:Keine Diskriminierungsmerkmale in Daten
Gemäß dem Allgemeinen Gleichbehandlungsgesetz (AGG) (§1 AGG) und Artikel 21 der Charta der Grundrechte der Europäischen Union (GRC) ist es unzulässig, Menschen aufgrund bestimmter persönlicher Merkmale zu benachteiligen. Diese Grundsätze gelten nicht nur für den Menschen als handelnde Instanz, sondern auch für den Einsatz automatisierter Systeme, etwa im Kontext von KI-basiertem Recruiting. Der EU AI Act verweist beispielsweise explizit auf Art. 21 GRC. Das AGG (§1) schützt vor Benachteiligung wegen:- der Rasse oder ethnischen Herkunft
- des Geschlechts
- der Religion oder Weltanschauung
- einer Behinderung
- des Alters
- der sexuellen Identität
- Geschlecht
- Rasse
- Hautfarbe
- ethnischer oder sozialer Herkunft
- genetischen Merkmalen
- Sprache
- Religion oder Weltanschauung
- politischer oder sonstiger Anschauung
- Zugehörigkeit zu einer nationalen Minderheit
- Vermögen
- Geburt
- Behinderung
- Alter
- sexueller Ausrichtung
- Staatsangehörigkeit
Keine verzichtbaren “Hoch-Risiko-Proxies” in Daten
Die Entfernung direkter Diskriminierungsmerkmale aus Daten (in Training und Nutzung) ist nicht hinreichend zur Vermeidung von Diskriminierungsmustern. Leistungsstarke KI-Modelle wie das unsere sind in der Lage Diskriminierungsmerkmale auch aus sehr schwach korrelierten anderen Merkmalen abzuleiten und dadurch entsprechende Muster zu lernen. Ein relativ offensichtliches Beispiel: Eine KI könnte aus der Bezeichnung einer Bildungseinrichtung Rückschlüsse auf die ethnische Herkunft ziehen. Solche indirekten Merkmale werden Proxies oder Proxy-Merkmale genannt. Wir klassifizieren Attribute unserer Daten im Hinblick auf ihr Risiko, als Proxy auf diese Weise zu Diskriminierung beizutragen. Muss dieses Risiko als hoch bewertet werden, entfernen wie die Merkmale, sofern sie nicht unbedingt für die Funktionsfähigkeit des KI-Modells erforderlich sind. Dies sind insbesondere:- Namensbestandteile
- Arbeitsort
- Zeitpunkte/Jahreszahlen die länger als 10 Jahre zurückliegen (als Proxy für Alter)
Debiasing-Technologie
Selbst wenn die oben beschriebenen datenbezogenen Maßnahmen gewissenhaft umgesetzt werden, ist das noch keine Garantie dafür, dass die Ergebnisse des Modells vollständig diskriminierungsfrei sind. Erstens kann das Modell auch aus schwachen Proxies unter Umständen Schlüsse auf Diskriminierungsmerkmale ziehen. Zweitens sind nicht alle starken Proxies für die Funktionsfähigkeit des Modells verzichtbar. Es ist deshalb erforderlich, auf Modellebene (in Abgrenzung zur Datenebene) Maßnahmen zu ergreifen. Diese Maßnahmen werden als Debiasing bezeichnet.Was ist Debiasing?
Debiasing bezeichnet Maßnahmen um diskriminierende Strukturen in KI-Modellen aufzudecken und ihnen technisch entgegenzuwirken. Es existieren einige erprobte Vorgehensweisen aus Wissenschaft und Praxis, die allerdings nicht plug&play angewendet werden können. Die Umsetzung erfordert eine Anpassung an das konkrete Modell, den Anwendungskontext sowie die betroffenen Verzerrungstypen. Die wissenschaftliche Auseinandersetzung mit KI-Bias und Debiasing ist aktuell weiterhin in vollem Gange und damit dynamisch. Wir halten aktuelle Entwicklungen kontinuierlich im Blick und tragen mit eigener Forschung und Entwicklung dazu bei.Unsere eigene Forschung und Entwicklung zu Debiasing
Wir haben eine Technologie zur aktiven Entfernung von Bias entwickelt, die speziell auf unser KI-Modell angepasst ist. Diese Technologie greift den neuesten Stand der technik auf und ergänzt diesen durch innovative Eigenentwicklungen. Unsere Debiasing-Technologie basiert auf einem Zusammenspiel des Basis-KI-Modells mit zwei weiteren KI-Modellen: Vereinfachend lässt sich die Wirkungsweise so beschreiben: nach dem Training des Basis-Modells (zur Erstellung der Shortlists) wird ein weiteres Modell darauf ausgerichtet, aus bestimmten Zwischenergebnissen des Basis-Modells Diskriminierungsmerkmale so präzise wie möglich zu erkennen (“Diskriminator”). Zusätzlich werden an spezifischen Stellen des Basismodells Komponenten integriert, die als Gegenspieler des Diskriminators dienen. Sie sollen die (Zwischen-)Ergebnisse des Basismodells so modifizieren, dass die Ergebnisqualität hoch bleibt, der Diskriminator allerdings an der Erkennung von Diskriminierungsmerkmalen gehindert wird. Diese Komponenten bezeichnen wir als “Immunsystem” des Modells. Diskriminator und Immunsystem werden simultan trainiert bis Erkennung von Diskriminierungsmerkmalen nicht mehr wirksam möglich ist. Das Immunsystem “verbleibt” im Modell und sorgt im Produktivbetrieb für diskriminierungsfreie Ergebnisse.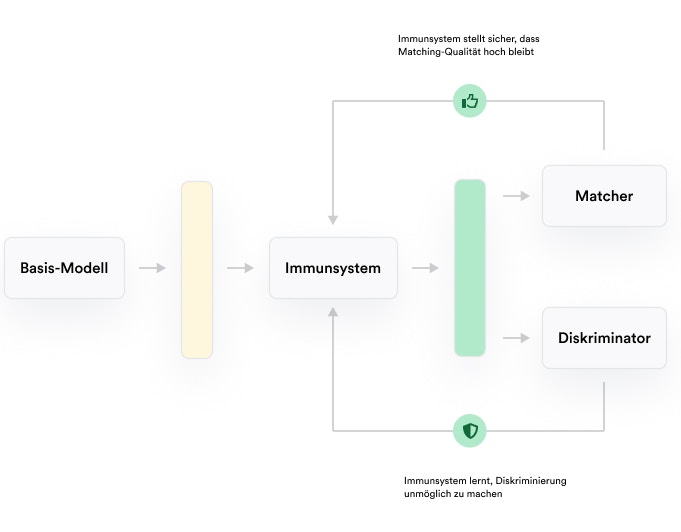
Häufige Fragen
Wie stellt skillconomy sicher, dass keine Diskriminierung durch KI erfolgt?
Wie stellt skillconomy sicher, dass keine Diskriminierung durch KI erfolgt?
Wir verfolgen einen mehrschichtigen Ansatz:
- Keine direkten Diskriminierungsmerkmale in Trainings- oder Nutzungsdaten
- Eliminierung starker Proxies (z. B. Name, Alter, Standort)
- Einsatz einer eigenentwickelten Debiasing-Technologie
- 100% menschliche Kontrolle der finalen Ergebnisse
So stellen wir sicher, dass Diskriminierung systematisch erkannt und verhindert wird.
Welche Merkmale gelten rechtlich als diskriminierungssensibel?
Welche Merkmale gelten rechtlich als diskriminierungssensibel?
Laut AGG (§1) und Art. 21 der EU-Grundrechtecharta dürfen u. a. folgende Merkmale nicht zu Benachteiligung führen:
Geschlecht, ethnische Herkunft, Religion, Behinderung, Alter, sexuelle Identität, Sprache, politische Anschauung, Vermögen oder Staatsangehörigkeit.
Geschlecht, ethnische Herkunft, Religion, Behinderung, Alter, sexuelle Identität, Sprache, politische Anschauung, Vermögen oder Staatsangehörigkeit.
Wie geht skillconomy mit Proxy-Merkmalen um?
Wie geht skillconomy mit Proxy-Merkmalen um?
Wir analysieren jedes Datenattribut systematisch auf sein Risiko, als Proxy für geschützte Merkmale zu wirken.
Hochrisiko-Proxies wie Namensbestandteile, Abschlussjahrgänge oder Arbeitsorte werden konsequent entfernt – sofern nicht unbedingt für die Modellfunktion notwendig.
Hochrisiko-Proxies wie Namensbestandteile, Abschlussjahrgänge oder Arbeitsorte werden konsequent entfernt – sofern nicht unbedingt für die Modellfunktion notwendig.
Was bedeutet 'Debiasing' im Kontext von KI?
Was bedeutet 'Debiasing' im Kontext von KI?
Debiasing bezeichnet Verfahren zur technischen Entfernung von Diskriminierungsmustern in Modellen.
Dabei kommen u. a. spezielle Architekturen zum Einsatz, die geschützte Merkmale neutralisieren, ohne die Ergebnisqualität wesentlich zu beeinträchtigen.
Dabei kommen u. a. spezielle Architekturen zum Einsatz, die geschützte Merkmale neutralisieren, ohne die Ergebnisqualität wesentlich zu beeinträchtigen.
Was ist das Besondere an der Debiasing-Technologie von skillconomy?
Was ist das Besondere an der Debiasing-Technologie von skillconomy?
Wir nutzen ein eigenes Verfahren, das ein Basis-KI-Modell, einen Diskriminator und ein sogenanntes ‘Immunsystem’ kombiniert.
Ziel ist es, diskriminierende Muster so zu neutralisieren, dass sie vom Diskriminator nicht mehr erkannt werden – bei gleichzeitig hoher Modellqualität.
Ziel ist es, diskriminierende Muster so zu neutralisieren, dass sie vom Diskriminator nicht mehr erkannt werden – bei gleichzeitig hoher Modellqualität.
Werden eure KI-Ergebnisse überprüft?
Werden eure KI-Ergebnisse überprüft?
Ja – wir verfolgen einen 100%-Human-in-the-Loop-Ansatz.
Alle Shortlists werden durch erfahrene Recruiter:innen vollständig geprüft, bevor eine Ansprache erfolgt.
Alle Shortlists werden durch erfahrene Recruiter:innen vollständig geprüft, bevor eine Ansprache erfolgt.
Ist eure KI damit völlig diskriminierungsfrei?
Ist eure KI damit völlig diskriminierungsfrei?
Kein System ist perfekt – auch nicht unsere KI.
Aber wir setzen alles daran, Diskriminierung zu erkennen und wirksam zu vermeiden – durch Technik, Aufsicht und ethische Leitlinien.
Aber wir setzen alles daran, Diskriminierung zu erkennen und wirksam zu vermeiden – durch Technik, Aufsicht und ethische Leitlinien.